")


 Model Created for Robotics")



Transformers are at the forefront of modern artificial intelligence, powering systems that understand and generate human language. They form the backbone of several influential AI models, such as Gemini, Claude, Llama, GPT-4, and Codex, which have been instrumental in various technological advances. However, as these models grow in size & complexity, they often exhibit unexpected behaviors, some of which may be problematic. This challenge necessitates a robust framework for understanding and mitigating potential issues as they arise.
One significant problem in transformer-based models is their tendency to scale in complexity, making it difficult to predict and control their outputs. This unpredictability can lead to outputs that are not only unexpected but occasionally harmful, raising concerns about the safety and reliability of deploying these models in real-world scenarios. The issue’s core lies in the models’ open-ended design, which, while allowing for flexible and powerful applications, also leads to a broad scope for unintended behaviors.

Efforts have been made to demystify the inner workings of transformers through mechanistic interpretability to address these challenges. This approach involves breaking down the intricate operations of these models into more comprehensible components, essentially attempting to reverse-engineer the complex mechanisms into something that can be easily analyzed and understood. Traditional methods have achieved some success in interpreting simpler models, but transformers, with their deep and intricate architecture, present a more formidable challenge.
Researchers from Anthropic proposed a mathematical framework to simplify the understanding of transformers by focusing on smaller, less complex models. This approach reinterprets the operation of transformers in a mathematically equivalent way, which is easier to manage and understand. The framework specifically examines transformers with no more than two layers and focuses exclusively on attention blocks, ignoring other common components like multi-layer perceptrons (MLPs) for clarity and simplicity.

The research demonstrated that this new perspective allows a clearer understanding of how transformers process information. Notably, it highlighted the role of specific attention heads, termed ‘induction heads,’ in facilitating what is known as in-context learning. These heads develop significant capabilities only in models with at least two attention layers. By studying these simpler models, researchers could identify and describe algorithmic patterns that could potentially be applied to larger, more complex systems.
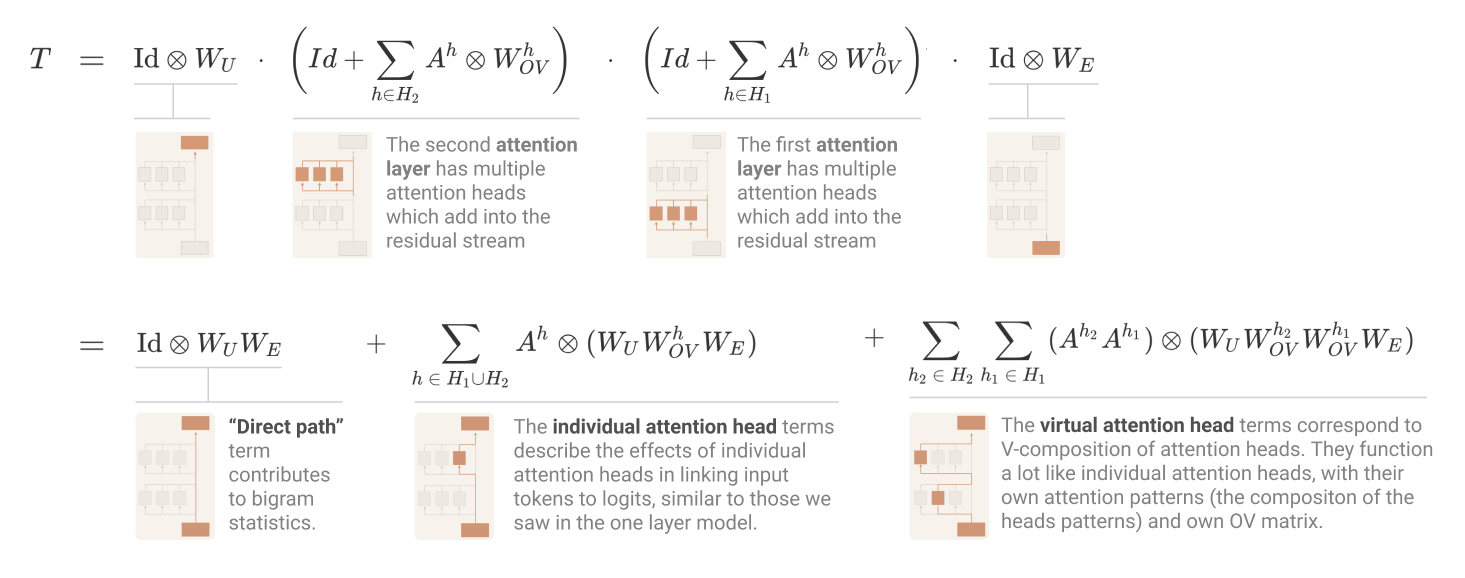
Empirical results from this study provided quantifiable insights into the functionality of these models. For instance, it was shown that zero-layer transformers primarily model bigram statistics directly accessible from the weights. In contrast, one and two-layer attention-only transformers exhibit more complex behaviors through the composition of attention heads. The two-layer models, in particular, use these compositions to create sophisticated in-context learning algorithms, significantly advancing the understanding of how transformers learn and adapt.
In conclusion, this research offers a promising path toward enhancing the interpretability and, consequently, the reliability of transformer models. By developing a framework that simplifies the complex operations of transformers into more manageable and understandable components, the research team has opened up new possibilities for improving model safety and performance. The insights from studying smaller models lay the groundwork for anticipating and mitigating the challenges of larger, more powerful systems, ensuring that transformers do so innovatively and securely as they evolve.



